¿Como va vuestro día? El mío de estudio , y he querido despejarme haciendo esta entrada.
El tema de hoy trata sobre la estadística inferencial , el muestreo y la estimación. Llamamos inferencia estadística a el conjunto de procedimientos que nos deja pasar lo particular a lo general.Si la muestra es elegida al azar , es un muestreo probabilístico y el error asociado es un error aleatorio. En cambio si la muestra no es elegida al azar, no hay posibilidad de evaluar el error.La medida que queremos obtener de la población se llama parámetro , y la medida de la variable que obtenemos se llama estimador. Para pasar de el estimador a el parámetro nos hace falta la inferencia.
El error estándar es la medida para captar la variabilidad de los valores del estimador y la fórmula para calcularla es :
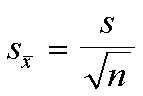
Después tenemos el teorema central de límite, se usa para estimadores que pueden ser expresados como suma de valores muestrales , cuyos valores de su distribución siguen una distribución normal con media de la población y desviación típica igual al error estándar del estimador.
También tenemos los intervalos de confianza que son un medio para conocer el parámetro de una población midiendo el error aleatorio.
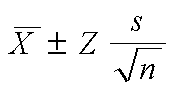
Hay diferentes tipos de muestreo:
-Probabilístico:
- Aleatorio simple: por ejemplo por un sorteo, o eligiendo números al azar.
- Aleatorio sistemático : es una variación del simple.
- Estratificado: se subdivide a la población en subgrupos.
- Conglomerado : se usa cuando no hay una lista detallada , se eligen subgrupos en vez de personas.
- Por cuotas : la muestra se selecciona considerando algunas variables como la edad o el sexo.
- Accidental : se utilizan las personan disponibles en el momento de la investigación.
- Conveniencia : según el interés del investigador.
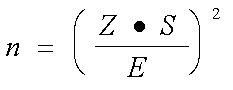
Ya no queda nada para acabar esta aventura,
¡Hasta mañana chatos!
No hay comentarios:
Publicar un comentario